0.概述
信息论与信息熵是 AI 或机器学习中非常重要的概念,我们经常需要使用它的关键思想来描述概率分布或者量化概率分布之间的相似性。
我们从最基本的自信息和信息熵到交叉熵讨论了信息论的基础,再由最大似然估计推导出 KL 散度而加强我们对量化分布间相似性的理解。
1.自信息
香农熵的基本概念就是所谓的一个事件背后的自信息(self-information),有时候也叫做不确定性。自信息的直觉解释如下,当某个事件(随机变量)的一个不可能的结果出现时,我们就认为它提供了大量的信息。相反地,当观察到一个经常出现的结果时,我们就认为它具有或提供少量的信息。
例如:
在硬币抛掷实验中,1bit信息代表单独抛掷一个硬币的两个可能的结果。
假如连续三次投掷硬币,一共有2^3=8种可能的结果,每种结果的可能性为0.5^3=0.125。
所以这次实验的自信息为-log_2(0.125) = 3,也就是需要3bit来表示其信息,
这样我们就能够看出,小概率对应着较高的自信息,其定义如下图所示。
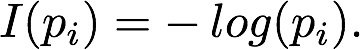
上面对数的底数可以为2,但是通常都使用10或者e方便计算,影响不大,因为底数不同仅仅是前面的系数不同。
根据公式,我们可以看出,较小的概率对应着较高的自信息。
当我们面对连续随机变量的情况下,我们针对三种不同的概率密度函数考虑了其对应的信息函数。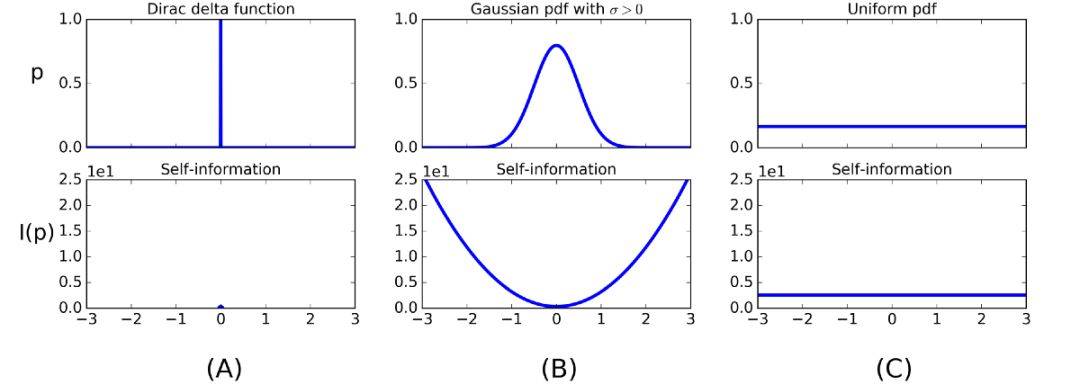
2.香农熵(信息熵)
我们到现在一直讨论的都是自信息。在正常的硬币实验中,自信息实际上都等于香农熵,因为所有的结果都是等概率出现的。通常,香农熵是变量的所有可能结果的自信息的期望值。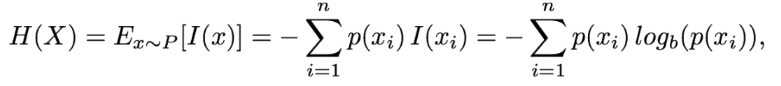
和之前的一样其底数b可以为任意数值。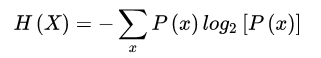
推导之后为上面的公式,底数可以为任意值。
上面的三个连续变量分别为冲击函数(0),高斯分布(174)和均匀分布(431),可以看出,越寛的分布有越高的信息熵。例如,高斯分布中,自信息曲线下面的面积远大于均匀分布,但是,需要经过概率加权处理。
3.交叉熵
交叉熵是用来比较两个概率分布p和q的数学工具,和香农熵类似,交叉熵为在概率p的情况下,q的自信息-log(q)的期望。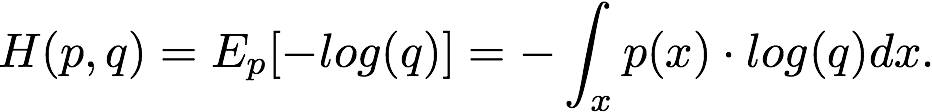
在信息论中,这个量值代表用q编码方式去编码服从q分布的事件,我们所需要的信息bit数。这是一个衡量概率分布相似性的工具,经常作为损失函数。
同时,交叉熵等于KL散度减去信息熵,当我们最小化交叉熵的时候,后面的信息熵是一个常量,所以能够省略,在这种情况下,交叉熵等于KL散度,因为KL散度能够简单的从最大似然估计推导出來,之后会有以MLE推导KL散度的表达式。
4.KL散度
与交叉熵紧密相关,KL散度是另一个在机器学习中衡量相似度的量。
从q到p的KL散度如下图所示。
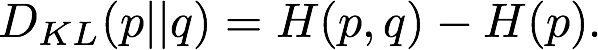
用q来近似p的时候造成的信息损失。和上面的交叉熵相比,减了一个常数项,从优化的目标进行考虑,两者是等价的。其属性为,当p和q相同的时候,KL散度的数值为0.
还有,KL散度为非负的,二期衡量的是两个分布之间的差异,通常用来分布之间的某种距离。然而,并未真的距离,因为它不是对称的。
5.通过极大似然估计推导KL散度
参考李宏毅教授的讲解中,假如给定一个样本数据的分布P_data(x)和生成数据的分布P_g(x;θ)
上面的推导过程中,我们需要最大化似然函数,然后对最大似然函数取对数,然后将乘法转换为加法,接着转换为期望,然后减去信息熵,就得到了KL散度。