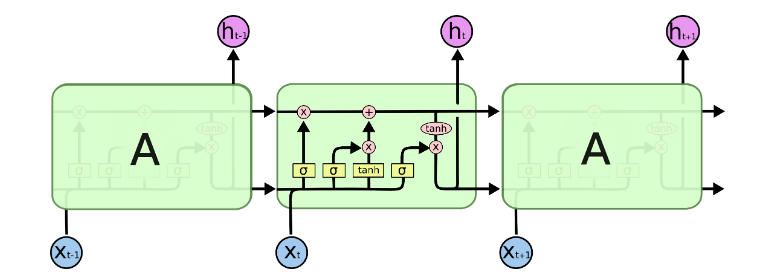
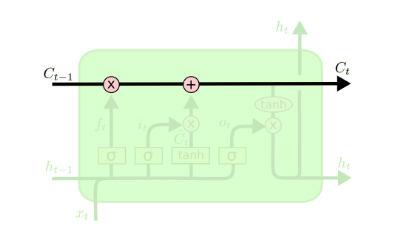
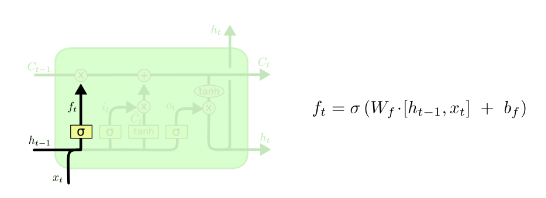
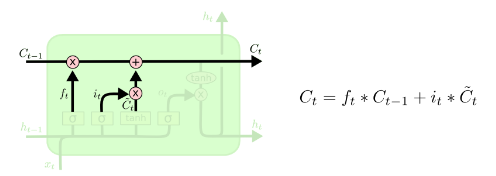
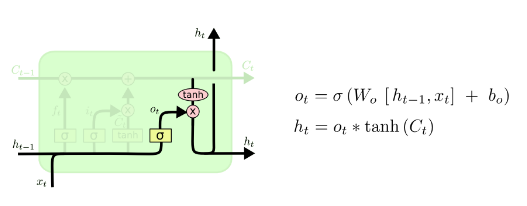
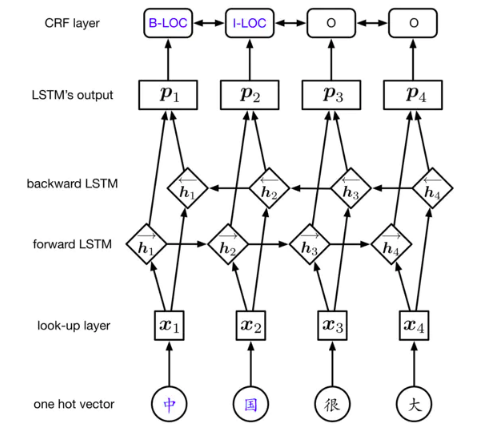
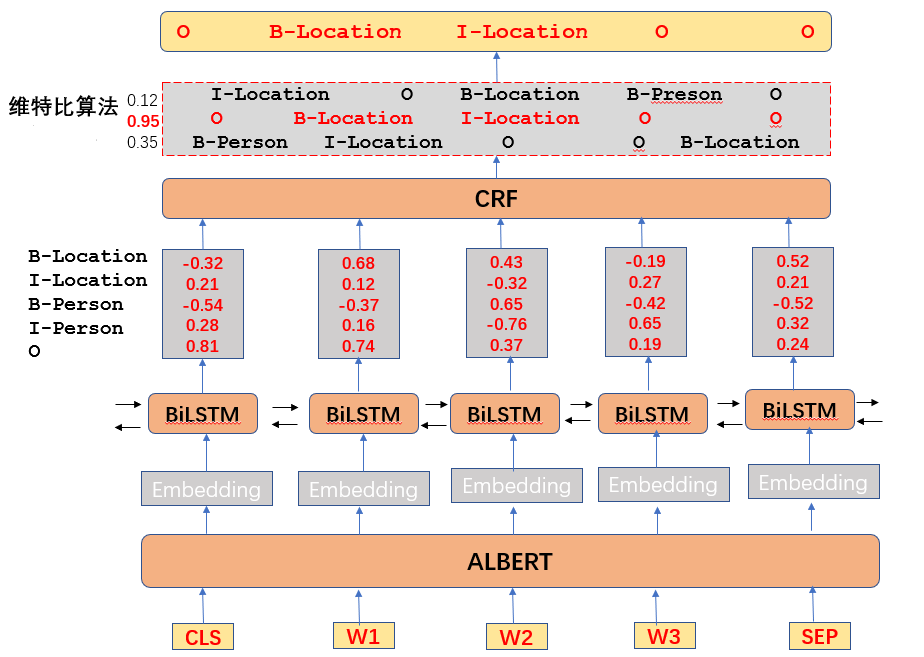
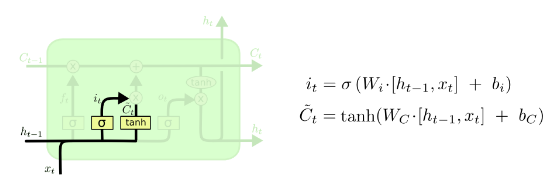input_size – The number of expected features in the input x
hidden_size – The number of features in the hidden state h
num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two LSTMs together to form a stacked LSTM, with the second LSTM taking in outputs of the first LSTM and computing the final results. Default: 1
bias – If False, then the layer does not use bias weights b_ih and b_hh. Default: True
batch_first – If True, then the input and output tensors are provided as (batch, seq, feature). Default: False
dropout – If non-zero, introduces a Dropout layer on the outputs of each LSTM layer except the last layer, with dropout probability equal to dropout. Default: 0
bidirectional – If True, becomes a bidirectional LSTM. Default: False
with open("README.md","r") as fh: long_description = fh.read()
setuptools.setup( name = "Emir-Liu-packet", #distribution name of package version = "0.0.1", author = "Emir-Liu", author_email = "egliuym@gmail.com", description = "my first test packet", # a short,one-sentence summary long_description = long_description, # the long description is loaded from README.md long_description_content_type = "text/markdown", url = "https://emir-liu.github.io/", # URL of the homepage of the project packages = setuptools.find_packages(), # a list of all python import packages that should be included in the destribution package classifiers = [ "Programming Language :: Python :: 3", "License :: OSI Approved :: MIT License", "Operating System :: OS Independent", ], # some additional metadata about package ,at least license ,operating system and verson of python python_requires = '>=3.0', )